


出品|搜狐科技
作者|张雅婷
随着DeepSeek的爆火,公众对AI幻觉的担忧也日益加剧。
比如,不少人通过DeepSeek辅助就医、撰写论文时发现,DeepSeek会“一本正经地胡说八道”,把一些专有名词“张冠李戴”,用户难以发现DeepSeek的“幻觉陷阱”。
来自Vectara机器学习团队的幻觉测试显示,DeepSeek-R1的幻觉率高达14.3%,显著高于DeepSeek-V3的3.9%,也远远超过行业的其他推理模型,比如OpenAI-o1的测试结果是2.4%。
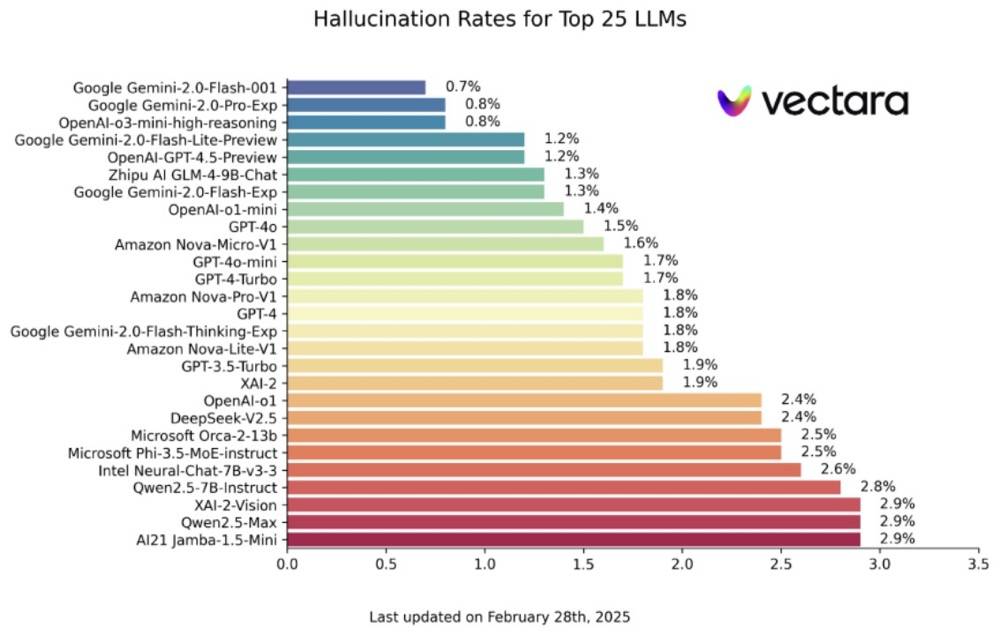
这种AI大模型生成内容与真实数据不符,或偏离用户指令的现象,会极大影响用户的使用体验。在医疗、法律、金融等对准确性要求高的领域,AI幻觉则会为企业带来严重后果。
DeepSeek-R1幻觉率为何高于行业其它推理模型?AI幻觉为何难以完全被消除?减少大模型幻觉的技术手段都有哪些?最近,搜狐科技与北京大学王选计算机研究所研究员、博士生导师赵东岩进行了深入交流。
赵东岩告诉搜狐科技,Vectara公司设计的是”忠实性幻觉”评估,检测生成摘要与原始文本的语义一致性,该测试主要测试模型摘要能力和指令遵循能力。
他表示,DeepSeek-R1这种推理模型,是通过生成中间推理步骤来增强问题解决能力,目标是解决复杂的推理任务。之所以在幻觉率方面的表现不好,可能是模型对齐做得不够。“我们在研究和使用过程中,R1复杂问题推理能力强大,往往比o3-mini好,但是有时instruction following的能力没有o3-mini好。”
赵东岩强调,DeepSeek等大模型的幻觉来自于本身的技术架构和基于统计的机器学习范式,是大模型的内生性缺陷。因此,可以说大模型的创造力与幻觉是相伴相生的。
他认为,要从根本上减少大模型幻觉,可以从让大模型学习运用已有知识来实现受限推理,向可控生成的方向进行突破。
以下为对话实录:
搜狐科技:来自Vectara机器学习团队的幻觉测试显示,DeepSeek-R1的幻觉率高达14.3%,显著高于V3的3.9%,也超过行业平均水平,这个背后可能有哪些原因呢?
赵东岩:根据相关信息,Vectara公司设计的是”忠实性幻觉”评估,检测生成摘要与原始文本的语义一致性或者看短文回答问题,该测试主要测试模型摘要能力和指令遵循能力。
推理模型,如 DeepSeek-R1 和 OpenAI 的 o3-mini,是通过生成中间推理步骤来增强问题解决能力,称为“长思维链”推理。这种方法目标是解决复杂的推理任务。
摘要任务是一个相对“简单”的任务,和推理能力并不对齐。R1在这个任务的幻觉大,我们推测主要是对齐这方面做得不够。我们在研究和使用过程中,R1复杂问题推理能力强大,往往比o3-mini好,但是有时instruction following的能力没有o3-mini好。
推理模型的“幻觉”整体比基座模型的“幻觉”大,一个原因可能是给定文本和模型自有知识的冲突。模型自己能力强,可能不按给定上下文去回答。现实中,说服一个聪明人更难些。
搜狐科技:在用户使用时发现,DeepSeek会编造专业文件,并且因为逻辑表达更好,幻觉很难识别出来,您觉得用户在使用时应该注意什么,来避免被大模型的幻觉“欺骗”?
赵东岩:这个只能多渠道验证信息来源。也可以使用多种语言询问,然后交叉验证。
搜狐科技:不少用户发现,DeepSeek在写作中展示出了惊人的创造力,大模型的创造力是不是一定会带来幻觉?大模型能做到既有创造力,又少幻觉吗?
赵东岩:简单来说,DeepSeek等大模型的幻觉来自于本身的技术架构和基于统计的机器学习范式,是大模型的内生性缺陷。因此,可以说大模型的创造力与幻觉是相伴相生的。
搜狐科技:大模型能做到既有创造力,又少幻觉吗?
赵东岩:对于事实性幻觉,如回答某事实性问题出错,这个得看问题的复杂程度。有部分原因是模型输出的随机性导致的(也是模型有创造力的源泉),这方面随着模型能力的增强,幻觉也会越来越小,但很难完全避免。
对于忠实性幻觉,如给定文本做摘要,这个要增强模型的指令遵循能力,有极大可能的缓解、甚至有条件消除(如可控生成)。这个过程并不会影响模型的创造力。一般来说,参数规模越大、模型能力越强,消除忠实性幻觉的机会就越大。
搜狐科技:随着大模型性能的发展,大模型幻觉的发展趋势是什么样的?
赵东岩:从海量数据的统计学习角度看,对同一个问题,有可能本身就有多种解答,或者共识不同(人类也没有在所有问题上达成共识),这些现象也会反映到模型的输出上。总体来看,模型性能越强,幻觉整体还是在减少,回答问题能力增强,也会生成更符合价值观的回答。
搜狐科技:大模型的幻觉问题,是否会导致其在行业应用面临较大的挑战?比如对准确率要求比较高的教育、医疗、金融等行业?
赵东岩:是的,所以在这些关键领域,模型的对齐效果非常关键。实践中,可以通过多次校验,对齐,RAG来改善大模型的幻觉问题。
搜狐科技:从技术上来说,常用减少大模型幻觉的手段有哪些呢?能否详细聊聊?
赵东岩:在输入层面,可以通过检索增强生成(RAG)的方法,通过引入外部知识库,在生成过程中检索相关信息,确保生成内容的准确性和时效性。
此外,可以将结构化的知识图谱集成到生成过程中,提供明确的事实支持,减少模型生成不准确或虚构信息的可能性。结合视觉和语言信息,增强模型对多种信息的校验,增强对事物理解的一致性,减少幻觉的发生。
在模型层面,可以精心设计输入提示,引导模型生成更符合预期的输出。如思维链引导模型逐步推理,减少幻觉的发生。在输出层面,可以通过投入更多的计算资源,输出多个结果,然后互相校验内容。
个人认为,要根本上缓解大模型幻觉,可以从如何让大模型学习运用已有知识来实现受限推理,向可控生成的方向实现突破。
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏






